Bienvenue
Dans cette étude de cas, vous allez explorer la popularité de votre propre prénom au fil du temps. En cours de route, vous maîtriserez certaines des fonctions les plus utiles pour isoler les variables, les observations et les valeurs d’un jeu de données :
select()etfilter(), permettent de selectionner des colonnes et des lignes d’un jeu de donnéesarrange(), permet de réorganiser les lignes de vos données|>, organise votre code en “pipes” (“flux” de traitement) faciles à lire
Ce module de cours utilise les packages de base du tidyverse, notamment
{ggplot2}, {tibble} et {dplyr},
ainsi que le package {prenoms}. Tous ces packages ont été
préinstallés et préchargés.
Cliquez sur le bouton “Suivant” pour commencer.
prenoms
La popularité d’un prénom au cours du temps
## `summarise()` has regrouped the output.
## `summarise()` has regrouped the output.
## ℹ Summaries were computed grouped by name, year, and sex.
## ℹ Output is grouped by name and year.
## ℹ Use `summarise(.groups = "drop_last")` to silence this message.
## ℹ Use `summarise(.by = c(name, year, sex))` for per-operation grouping
## (`?dplyr::dplyr_by`) instead.Nous avons au préalable modifié pour les besoins du cours les données
de prenoms (comparé à celles disponibles dans le package)
pour faciliter les tâches qui viennent. Voici maintenant le format des
données prenoms (prop représente la proportion
de bébés d’un sexe donné qui ont eu ce prénom cette année précise) :
## # A tibble: 769,855 × 5
## year sex name n prop
## <int> <chr> <chr> <int> <dbl>
## 1 1980 M A Alexandru 1 0.0000195
## 2 1980 M A Bonnaroth 1 0.0000195
## 3 1980 F A Charlotte 1 0.0000208
## 4 1980 F A Dominique 1 0.0000208
## 5 1980 F A Elisabeth 2 0.0000415
## 6 1980 F A Francoise 1 0.0000208
## 7 1980 M A Geoffroy 1 0.0000195
## 8 1980 M A Guillaume 1 0.0000195
## 9 1980 F A Icha 1 0.0000208
## 10 1980 F A Maria 1 0.0000208
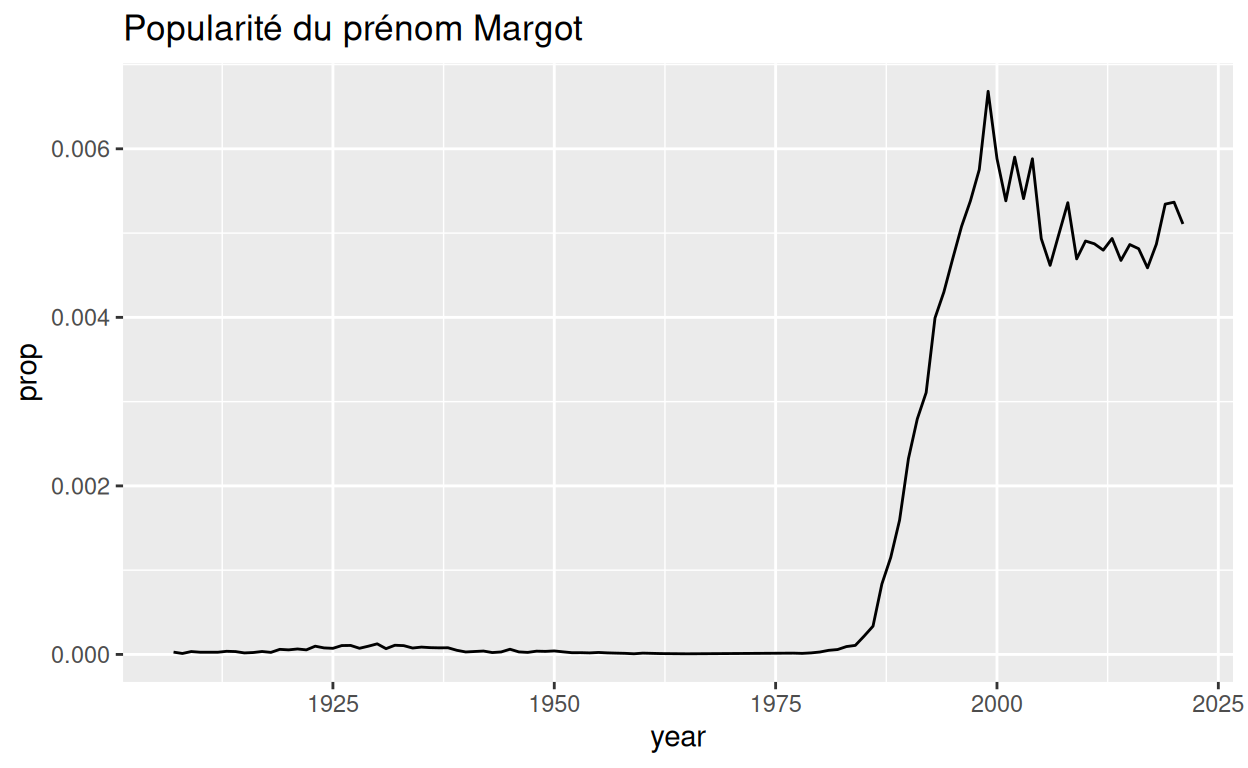
## # ℹ 769,845 more rowsVous pouvez utiliser les données de prenoms pour créer
des graphiques comme celui-ci, qui révèlent la popularité d’un prénom au
cours du temps, peut-être votre prénom.
Avant d’afficher les informations à propos d’un autre prénom, vous
devrez réduire prenoms. Pour le moment, il y a plus de
lignes dans prenoms que vous n’en avez besoin pour
construire un graphique à propos d’un seul prénom.
Exemple
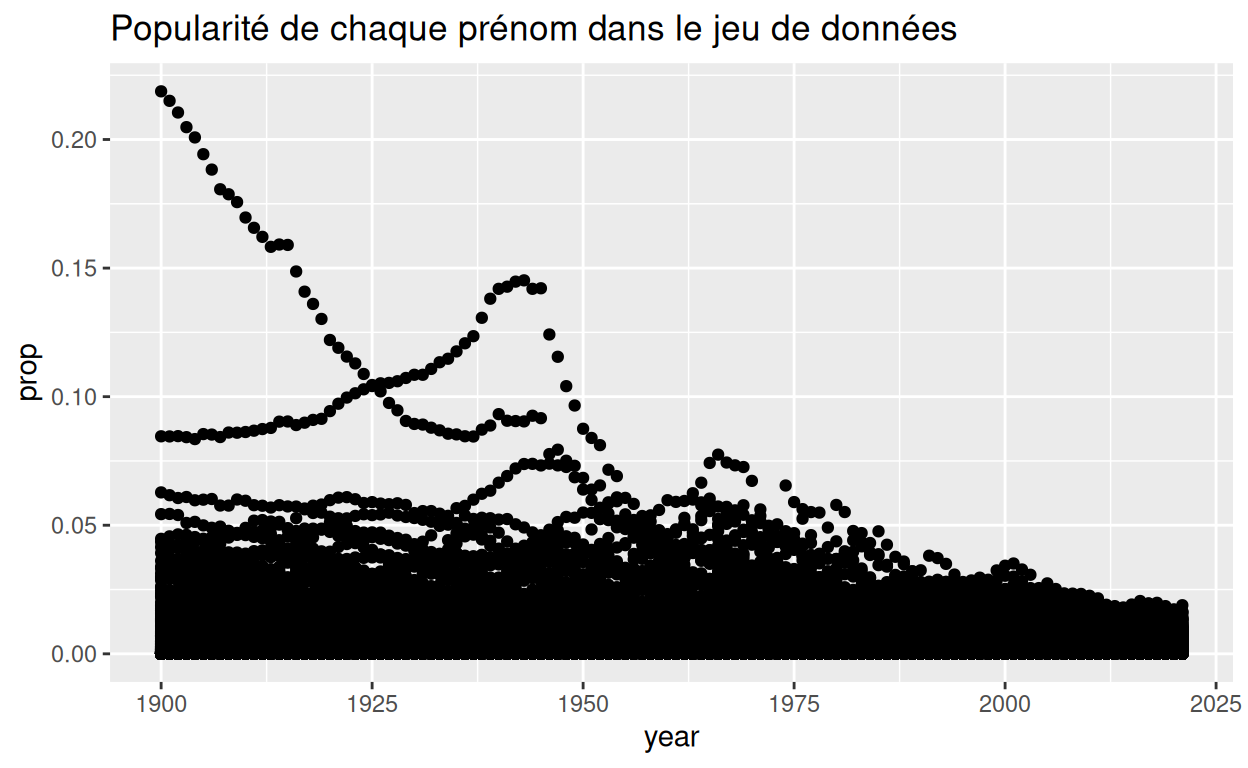
Voyons la façon dont nous avons créé le graphique ci-dessus : nous avons commencé avec le jeu de données entier qui, si il était affiché sous la forme d’un nuage de points, aurait ressemblé à ceci :
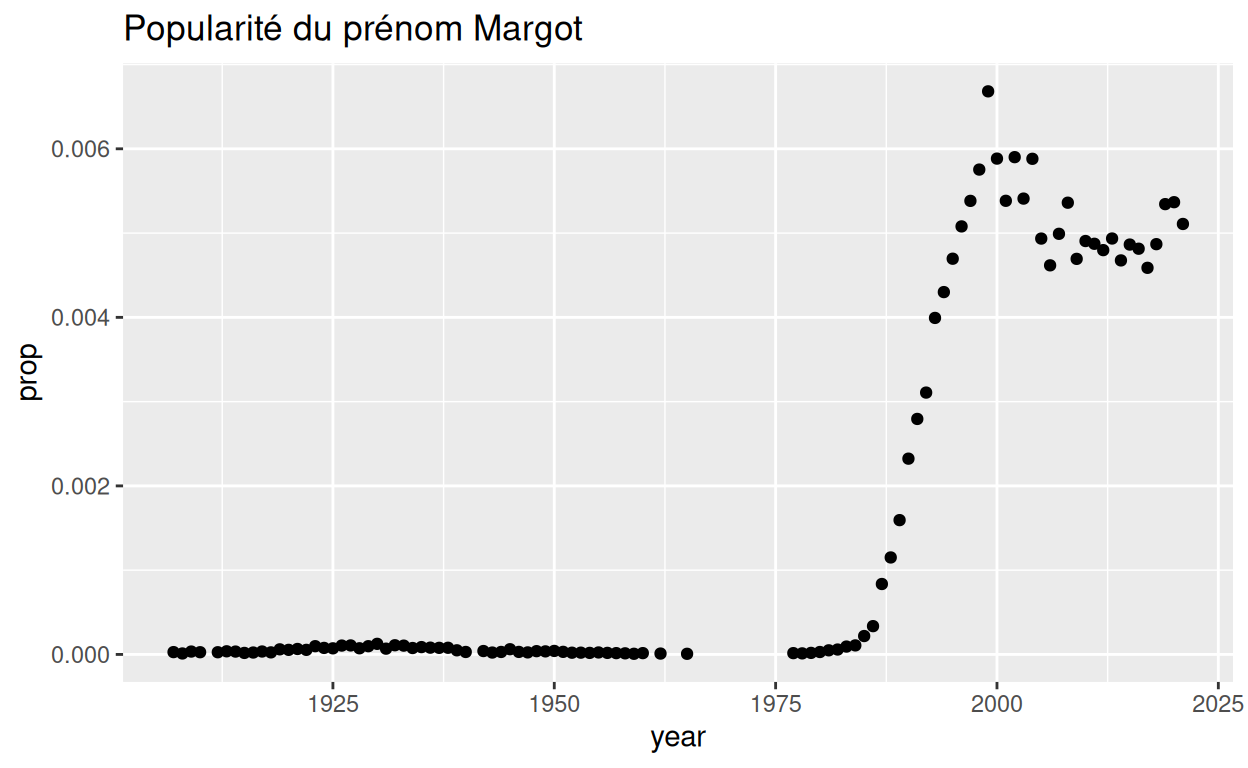
Nous avons ensuite réduit les données aux seules lignes contenant le prénom “Margot” de sexe féminin, avant de tracer les données avec un graphique. Voici à quoi ressemblent les lignes avec ce prénom comme un nuage de points.
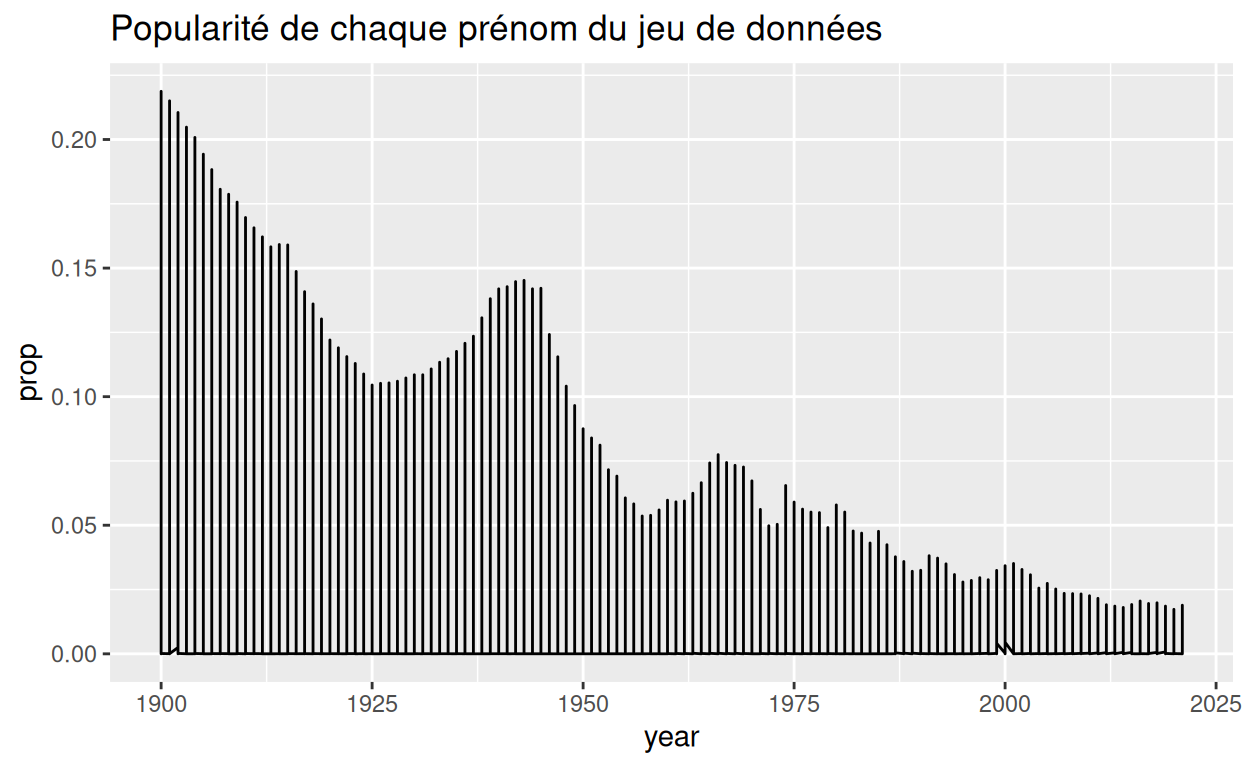
Si nous avions sauté cette étape, notre graphique linéaire aurait connecté tous les points du jeu de données entier, créant un graphique non informatif.
Votre objectif dans cette section est de répéter ce processus pour un autre prénom, par exemple le votre. En cours de route, vous apprendrez un ensemble de fonctions qui isolent les informations dans un jeu de données.
Isoler des données
Ce type de tâche se produit souvent en Data science : vous devez extraire les données d’une table avant de pouvoir l’utiliser. Vous pouvez effectuer cette tâche rapidement avec trois fonctions fournies dans le package {dplyr} :
- select() - qui selectionne des colonnes d’un jeu de données
- filter() - qui extrait des lignes d’un jeu de données
- arrange() - qui déplace les lignes importantes vers le haut d’un jeu de données
Chaque fonction prend un data.frame ou un tibble et renvoie un nouveau data.frame ou un tibble en sortie.
select()
select() selectionne les colonnes d’un jeu de données et
retourne les colonnes comme un nouveau jeu de données. Pour utiliser
select(), passez-lui le nom du jeu de données dont il faut
extraire les colonnes, puis les noms des colonnes à extraire.
Aparté pour les déjà utilisateurs de R qui découvriraient le
tidyverse : les noms de colonnes n’ont pas besoin d’apparaître entre
guillemets ni d’être précédés par un $. En effet,
select() sait les trouver dans le jeu de données que vous
lui fournissez.
Exercice - select()
Utilisez l’exemple ci-dessous pour avoir une idée du fonctionnement
de select(). Pouvez-vous sélectionner uniquement la colonne
name ? Et comment extraire name et
year ? Que diriez-vous de sélectionner toutes les colonnes
sauf prop ?
select(prenoms, name, sex)# A tibble: 769,855 × 2
name sex
<chr> <chr>
1 A Alexandru M
2 A Bonnaroth M
3 A Charlotte F
4 A Dominique F
5 A Elisabeth F
6 A Francoise F
7 A Geoffroy M
8 A Guillaume M
9 A Icha F
10 A Maria F
# ℹ 769,845 more rowsselect(prenoms, name)
select(prenoms, name, year)
select(prenoms, year, sex, name, n)Outils de select()
Il existe également une série d’outils appelés “helpers” fournis avec
select() et destinés à nous faciliter la vie. Par exemple,
si vous placez un signe ‘-’ devant un nom de colonne,
select() renverra toutes les colonnes sauf cette colonne.
Pouvez-vous prédire comment le signe moins va fonctionner ici ?
select(prenoms, -year, -prop)Le tableau ci-dessous résume les autres outils de
select() disponibles dans {dplyr}. Étudiez-le, puis cliquez
sur “Continue” pour tester votre compréhension.
| Outil | Utilisation | Exemple |
|---|---|---|
| - | Exclusion de colonnes | select(prenoms, -sex) |
| : | Sélection des colonnes entre 2 colonnes spécifiques (inclusive) | select(prenoms, year:n) |
| contains() | Sélection des colonnes qui contiennent une chaîne de caractère spécifique | select(prenoms, contains("n")) |
| ends_with() | Sélection des colonnes qui se terminent par une chaîne de caractère spécifique | select(prenoms, ends_with("n")) |
| matches() | Sélection des colonnes qui correspondent à une expression réguliere | select(prenoms, matches("n")) |
| num_range() | Sélection des colonnes avec un suffixe numérique dans l’étendue demandée | Pas applicable à prenoms |
| one_of() | Sélection des colonnes dont le nom apparaît dans l’ensemble demandé | select(prenoms, one_of(c("sex", "name"))) |
| starts_with() | Sélection des colonnes qui commencent par une chaîne de caractère spécifique | select(prenoms, starts_with("n")) |
Quiz select()
filter()
filter() extrait les lignes d’un jeu de données et les
renvoie comme un nouveau jeu de données. Comme avec
select(), le premier argument de filter() doit
être un jeu de données dont on souhaite extraire des lignes. Les
arguments qui suivent doivent être des tests logiques :
filter() renverra chaque ligne pour laquelle les tests
renverront TRUE (c’est-à-dire pour lesquelles la condition
que l’on teste est vérifiée).
filter() en action
Par exemple, le bloc de code ci-dessous renvoie chaque ligne avec le
prénom “Annie” dans prenoms.
filter(prenoms, name == "Annie")## # A tibble: 49 × 5
## year sex name n prop
## <int> <chr> <chr> <int> <dbl>
## 1 1980 F Annie 1102 0.0229
## 2 1981 F Annie 947 0.0200
## 3 1981 M Annie 1 0.0000196
## 4 1982 F Annie 820 0.0178
## 5 1982 M Annie 1 0.0000205
## 6 1983 F Annie 623 0.0140
## 7 1984 F Annie 519 0.0115
## 8 1985 F Annie 445 0.00997
## 9 1985 M Annie 1 0.0000208
## 10 1986 F Annie 381 0.00860
## # ℹ 39 more rowsTests logiques
Pour tirer le meilleur parti du filtre, vous devrez savoir comment utiliser les opérateurs de test logique de R, qui sont résumés ci-dessous.
| Opérateur logique | Tests | Exemple |
|---|---|---|
| > | x est-il supérieur que y ? |
x > y |
| >= | x est-il supérieur ou égal à y ? |
x >= y |
| < | x est-il inférieur à y ? |
x < y |
| <= | x est-il inférieur ou égale à y ? |
x <= y |
| == | x est-il égal à y ? |
x == y |
| != | x est-il différent de y ? |
x != y |
| is.na() | x est-il une information manquante NA
? |
is.na(x) |
| !is.na() | x n’est pas une information manquante
NA? |
!is.na(x) |
Exercice - Opérateurs logiques
Voyez si vous pouvez utiliser les opérateurs logiques pour manipuler le code ci-dessous pour afficher :
- Tous les prénoms pour lequels
propest supérieure ou égale à 0.08 - Tous les enfants prénommés “Paulette”
- Tous les prénoms qui ont une valeur manquante pour
n(Astuce : cela devrait retourner un ensemble de données vide).
filter(prenoms, name == "Annie")filter(prenoms, prop >= 0.08)
filter(prenoms, name == "Paulette")
filter(prenoms, is.na(n))Deux erreurs courantes
Lorsque vous utilisez des tests logiques, il est une erreur très courante (même parmi les développeurs avertis). Elles apparaissent dans les blocs de code ci-dessous. Pouvez-vous les identifier ? Lorsque vous repérez une erreur, corrigez-la, puis exécutez le bloc pour confirmer que cela fonctionne comme attendu.
filter(prenoms, name = "Annie")filter(prenoms, name == "Annie")filter(prenoms, name == Annie)filter(prenoms, name == "Annie")Deux erreurs - Récapitulatif
Lorsque vous utilisez des tests logiques, veillez à rechercher ces deux erreurs courantes :
- utiliser
=au lieu de==pour tester l’égalité - oublier d’utiliser des guillemets lors de la comparaison de chaînes,
par ex.
name == Marie, au lieu dename == "Marie".
Combinaison de tests
Si vous fournissez plus d’un test à filter(),
filter() combinera les tests avec une instruction
et (&) : il ne renverra que les lignes
qui satisfont tous les tests.
Pour combiner plusieurs tests d’une manière différente, utilisez les opérateurs booléens de R. Par exemple, le code ci-dessous renverra tous les enfants prénommés Julie ou Antoinette.
filter(prenoms, name == "Julie" | name == "Antoinette")## # A tibble: 89 × 5
## year sex name n prop
## <int> <chr> <chr> <int> <dbl>
## 1 1980 F Antoinette 6 0.000125
## 2 1980 F Julie 2135 0.0443
## 3 1980 M Julie 1 0.0000195
## 4 1981 F Antoinette 1 0.0000211
## 5 1981 F Julie 1875 0.0396
## 6 1982 F Antoinette 4 0.0000866
## 7 1982 F Julie 1686 0.0365
## 8 1983 F Antoinette 3 0.0000673
## 9 1983 F Julie 1392 0.0312
## 10 1984 F Antoinette 1 0.0000221
## # ℹ 79 more rowsOpérateurs booléens
Vous pouvez trouver une liste complète des opérateurs booléens de base de R dans le tableau ci-dessous.
| Opérateur booléen | Signification | Exemple |
|---|---|---|
| & | Est-ce que les conditionsA et B sont
toutes les deux vraies ? |
A & B |
| |
Est-ce que l’ une ou les deux conditions A et
B sont vraies ? |
A | B |
| ! | Est-ce que A n’est pas vraie ? |
!A |
| xor() | Est-ce que l’ une et uniquement une des conditions
A et B est vraie ? |
xor(A, B) |
| %in% | Est-ce que x est dans l’ensemble a,
b, et c ? |
x %in% c(a, b, c) |
| any() | Est-ce que l’une des conditions A,
B, ou C est vraie ? |
any(A, B, C) |
| all() | Est-ce que toutes les conditions A,
B, ou C sont vraies ? |
all(A, B, C) |
Exercice - Combinaison de tests
Utilisez les opérateurs booléens pour modifier le bloc de code ci-dessous pour renvoyer uniquement les lignes qui contiennent :
- Les filles prénommées Agnès
- Les prénoms qui ont été données à exactement 5 ou 6 enfants en 1900
- Les prénoms Marie, Mariette ou Marine
filter(prenoms, name == "Julie" | name == "Antoinette")# A tibble: 89 × 5
year sex name n prop
<int> <chr> <chr> <int> <dbl>
1 1980 F Antoinette 6 0.000125
2 1980 F Julie 2135 0.0443
3 1980 M Julie 1 0.0000195
4 1981 F Antoinette 1 0.0000211
5 1981 F Julie 1875 0.0396
6 1982 F Antoinette 4 0.0000866
7 1982 F Julie 1686 0.0365
8 1983 F Antoinette 3 0.0000673
9 1983 F Julie 1392 0.0312
10 1984 F Antoinette 1 0.0000221
# ℹ 79 more rowsfilter(prenoms, name == "Agnès", sex == "F")
filter(prenoms, n == 5 | n == 6, year == 1900)
filter(prenoms, name %in% c("Marie", "Mariette", "Marine"))Deux erreurs courantes supplémentaires
Les tests logiques peuvent également être liés à deux erreurs fréquentes que nous allons explorer. Chacune est affichée dans un bloc de code ci-dessous. L’un des codes génère une erreur et l’autre est inutilement verbeux. Diagnostiquez les problèmes, puis corrigez le code.
filter(prenoms, 10 < n < 20)filter(prenoms, 10 < n, n < 20)filter(prenoms, n == 5 | n == 6 | n == 7 | n == 8 | n == 9)filter(prenoms, n %in% c(5, 6, 7, 8, 9))Deux erreurs courantes supplémentaires - Récapitulatif
Lorsque vous combinez plusieurs tests logiques, veillez à rechercher ces deux erreurs courantes :
- Réduire plusieurs tests logiques en un seul test sans utiliser d’opérateur booléen
- Utilisation répétitive de
|au lieu de%in%, par ex.x == 1 | x == 2 | x == 3au lieu dex %in% c (1, 2, 3)
arrange()
arrange() renvoie toutes les lignes d’un jeu données
réorganisées par les valeurs d’une colonne. Comme avec
select(), le premier argument de arrange()
doit être un jeu de données et les arguments restants sont les noms des
colonnes. Si vous donnez à arrange() un seul nom de
colonne, il renverra les lignes du jeu de données réorganisées de sorte
que la ligne avec la valeur la plus basse dans cette colonne apparaisse
en premier, la ligne avec la deuxième valeur la plus basse apparaisse en
deuxième, et ainsi de suite. Si la colonne contient des chaînes de
caractères, arrange() les placera par ordre
alphabétique.
Exercice - arrange()
Utilisez le bloc de code ci-dessous pour organiser les prénoms en
fonction de n. Pouvez-vous dire quelle est la plus petite
valeur de n?
arrange(prenoms, n)Gestion des ex-aequo
Si vous renseignez plusieurs noms de colonnes, arrange()
les utilisera successivement pour réorganiser les lignes qui ont des
valeurs identiques dans les colonnes précédentes. Complétez le code
ci-dessous avec la colonne prop pour illustrer ce
fonctionnement. Le résultat doit d’abord classer les lignes en fonction
de la valeur de n, puis réorganiser les lignes de chaque
valeur de n en fonction des valeurs de
prop.
arrange(prenoms, n)# A tibble: 769,855 × 5
year sex name n prop
<int> <chr> <chr> <int> <dbl>
1 1980 M A Alexandru 1 0.0000195
2 1980 M A Bonnaroth 1 0.0000195
3 1980 F A Charlotte 1 0.0000208
4 1980 F A Dominique 1 0.0000208
5 1980 F A Francoise 1 0.0000208
6 1980 M A Geoffroy 1 0.0000195
7 1980 M A Guillaume 1 0.0000195
8 1980 F A Icha 1 0.0000208
9 1980 F A Maria 1 0.0000208
10 1980 F A-Christiane 1 0.0000208
# ℹ 769,845 more rowsarrange(prenoms, n, prop)desc
Si vous préférez organiser les lignes dans l’ordre inverse,
c’est-à-dire des valeurs les plus grandes aux valeurs les
plus petites, entourez un nom de colonne avec la fonction
desc(). arrange() réordonnera les lignes des
plus grandes valeurs aux plus petites.
Ajoutez un desc() au code ci-dessous pour afficher le
prénom le plus populaire pour la plus grande année du jeu de données au
lieu de 1900 (la plus petite année du jeu de données).
arrange(prenoms, year, desc(prop))# A tibble: 769,855 × 5
year sex name n prop
<int> <chr> <chr> <int> <dbl>
1 1980 F Julie 2135 0.0443
2 1980 F Melanie 1788 0.0371
3 1980 F Karine 1718 0.0357
4 1980 M Eric 1634 0.0318
5 1980 F Genevieve 1524 0.0316
6 1980 F Isabelle 1481 0.0308
7 1980 M Jonathan 1546 0.0301
8 1980 M Sebastien 1472 0.0287
9 1980 F Caroline 1377 0.0286
10 1980 M Martin 1446 0.0282
# ℹ 769,845 more rowsarrange(prenoms, desc(year), desc(prop))Vous pensez avoir compris ? Cliquez sur “Continue” pour tester vos acquis.
Quiz arrange()
Quel prénom était le plus populaire pour un seul sexe en une seule
année ? Dans le bloc de code ci-dessous, utilisez arrange()
pour faire apparaître la ligne avec la plus grande valeur de
prop en haut du jeu de données.
arrange(prenoms, desc(prop))Arrangez maintenant prenoms pour que la ligne avec la
plus grande valeur de n apparaisse en haut du jeu de
données. Est-ce que ce sera la même ligne d’après vous ?
arrange(prenoms, desc(n))|>
Étapes
Remarquez comment chaque fonction de {dplyr} prend un jeu de données en entrée et renvoie un jeu de données en sortie. Cela rend les fonctions faciles à “brancher” les unes aux autres pour réaliser des suites d’étapes. Par exemple, vous pourriez :
- Filtrer les prénoms de bébé pour les garçons nés en 2018
- Sélectionner les colonnes
nameetndans le résultat - Organiser ces colonnes de sorte que les prénoms les plus populaires apparaissent en haut.
boys_2018 <- filter(prenoms, year == 2018, sex == "M")
boys_2018 <- select(boys_2018, name, n)
boys_2018 <- arrange(boys_2018, desc(n))
boys_2018## # A tibble: 8,744 × 2
## name n
## <chr> <int>
## 1 William 744
## 2 Liam 643
## 3 Logan 640
## 4 Thomas 606
## 5 Noah 579
## 6 Leo 546
## 7 Jacob 543
## 8 Felix 499
## 9 Edouard 494
## 10 Nathan 490
## # ℹ 8,734 more rowsRedondance
Le résultat nous montre les prénoms de garçons les plus populaires de
2018. Mais jetez un œil au code. Remarquez-vous comment nous recréons
boys_2018 à chaque étape afin que nous ayons quelque chose
à passer à l’étape suivante ?
Vous pouvez éviter de créer boys_2018 à chaque fois.
Pour cela, une première stratégie consiste à imbriquer vos fonctions les
unes dans les autres. Cependant, cela crée du code difficile à lire
:
arrange(select(filter(prenoms, year == 2018, sex == "M"), name, n), desc(n))Une autre façon d’écrire des séquences de fonctions est possible: le pipe |>. Le pipe peut être vu comme un flux, dans lequel nous réalisons une série d’opérations sur les données.
|>
L’opérateur pipe |> effectue la tâche suivante : il
passe l’objet à gauche en premier argument de la fonction à droite. Ou
en d’autres termes, x |> f(y) est identique à
f(x, y). Cette manière d’écrire du code facilite l’écriture
et la lecture d’une série de fonctions qui sont appliquées étape par
étape. Par exemple, nous pouvons utiliser le pipe pour réécrire notre
code ci-dessus :
prenoms |>
filter(year == 2018, sex == "M") |>
select(name, n) |>
arrange(desc(n))## # A tibble: 8,744 × 2
## name n
## <chr> <int>
## 1 William 744
## 2 Liam 643
## 3 Logan 640
## 4 Thomas 606
## 5 Noah 579
## 6 Leo 546
## 7 Jacob 543
## 8 Felix 499
## 9 Edouard 494
## 10 Nathan 490
## # ℹ 8,734 more rowsLorsque vous lisez le code, prononcez |> comme
“puis”. Si nous considérons que chaque nom de fonction est un verbe,
notre code ressemble à la déclaration : “Prenez les prénoms,
puis filtrez-les par année et par sexe, puis
sélectionnez les colonnes name et n,
puis organisez les résultats dans l’ordre descendant des
valeurs de n.”
{dplyr} facilite également l’écriture des pipes. Chaque fonction de {dplyr} renvoie un jeu de données qui peut être utilisé dans une autre fonction de {dplyr} (qui acceptera alors le jeu de données comme premier argument). En fait, les fonctions de dplyr sont écrites pour permettre l’usage du pipe : chaque fonction fait une tâche simple, et {dplyr} s’attend à ce que vous utilisiez des pipes pour combiner ces tâches simples pour produire des résultats plus sophistiqués.
Exercice - Pipes
Nous utiliserons des pipes pour le reste du module. Pratiquons un peu en écrivant un nouveau pipe dans le code ci-dessous. Le flux de traitement doit être le suivant :
- Filtrer les prénoms de bébé uniquement pour les filles nées en 2018
- Sélectionner les colonnes
nameetn - Organiser les résultats de manière à ce que les prénoms les plus populaires soient en haut dans le résultat.
Essayez d’écrire votre propre pipe, sans copier ni coller le code ci-dessus.
prenoms |>
filter(year == 2018, sex == "F") |>
select(name, n) |>
arrange(desc(n))Tester un autre prénom
Vous maîtrisez maintenant un ensemble de compétences qui vont vous
permettre de tracer facilement la popularité de n’importe quel prénom au
fil du temps (pourquoi pas le votre ?). Dans le bloc de code ci-dessous,
utilisez une combinaison de fonctions de {dplyr} et de {ggplot2} avec
|> pour :
- Réduire
prenomsaux seules lignes qui contiennent le prénom et le sexe que vous souhaitez étudier - Réduire le résultat aux seules colonnes qui apparaîtront dans votre graphique (pas strictement nécessaire, mais pratique pour avoir une meilleure visibilité)
- Tracer les résultats sous la forme d’un graphique linéaire avec
yearsur l’axe des x etpropsur l’axe des y
Notez que le premier argument de ggplot() est un jeu de
données. Cela signifie que vous pouvez ajouter ggplot()
directement à la fin d’un pipe. Cependant, vous devrez passer de
|> à + pour terminer l’ajout de couches à
votre graphique.
prenoms |>
filter(name == "Louis", sex == "M") |>
select(year, prop) |>
ggplot() +
aes(x = year, y = prop) +
geom_line() +
labs(title = "Popularité du prénom Louis")Récapitulatif
Ensemble, select(), filter() et
arrange() vous permettent de trouver rapidement les
informations disponibles dans vos données.
Le module suivant vous montrera comment calculer des informations implicites dans vos données, mais non disponibles telles quelles dans le jeu de données.
Dans ce module, vous continuerez à utiliser l’opérateur
|>, qui est une partie essentielle de la programmation
dans le tidyverse. Dans le tidyverse, les fonctions sont comme des
verbes : chacune accomplit une tâche simple. Vous pouvez combiner ces
tâches en un flux de traitements avec |> pour effectuer
des procédures complexes et personnalisées. C’est ainsi que les pipes
contribuent à rendre R intelligible, comme une langue parlée. Les
langues parlées sont en effet constituées de mots simples que vous
combinez en phrases complexes pour créer des pensées sophistiquées.