Bienvenue
Les données se présentent souvent sous la forme de plusieurs jeux de données liés les uns aux autres. Lorsque c’est le cas, les données seront plus faciles à analyser si vous joignez les différents jeux de données dans une seule table. Ce module vous apprendra plusieurs fonctions qui permettront de joindre des ensembles de données. Ces fonctions font quelque chose de sophistiqué : elles font correspondre les lignes d’un jeu de données aux lignes correspondantes d’un autre jeu de données, même si les lignes apparaissent dans un ordre différent. Les fonctions sont les suivantes :
left_join(),right_join(),full_join(), etinner_join()- qui rajoutent à une copie d’un jeu de données des informations provenant d’un second jeu de donnéessemi_join()etanti_join()- qui filtrent le contenu d’un jeu de données en fonction du contenu d’un second jeu de donnéesbind_rows(),bind_cols(), et d’autres opérations - qui combinent des jeux de données de manière plus simple
Chacune de ces fonctions est incluse dans le package {dplyr}, et non dans le package {tidyr}. Vous vous demandez donc peut-être pourquoi nous en parlons dans cet ensemble de module relatif aux tidy data (données ordonnées). C’est en fait car les jointures sont des composantes utilisées du rangement des données : vos données peuvent difficilement être ordonnées si les observations sont réparties dans plusieurs jeux de données dans lesquels elles sont enregistrées dans des ordres différents.
Ce module utilise les packages de base du tidyverse, notamment {dplyr}, ainsi que le package {nycflights13}. Tous ces packages ont été préinstallés et préchargés.
Cliquez sur le bouton “Suivant” pour commencer.
Jointures transformantes
Quelles compagnies aériennes ont les retards à l’arrivée les plus importants ?
Les retards de vol sont un aspect pénible des voyages en avion. Si vous avez pris l’avion quelques fois, vous avez probablement connu un vol retardé, ce qui peut vous amener à vous demander : est-il possible de prédire quels vols seront retardés ?
Le jeu de données flights du package
{nycflights13} fournit les détails de chaque vol qui a
décollé d’un aéroport qui dessert New York en 2013. Utilisons-le pour
explorer quelles compagnies aériennes ont les retards de vol les plus
importants.
flightsAvis - Quelles compagnies aériennes ont les plus importants retards à l’arrivée ?
La variable carrier de flights utilise un
code de transporteur pour identifier la compagnie aérienne qui a
effectué chaque vol. Cela nous permet de comparer le temps de retard
moyen par compagnie aérienne :
- Supprimez toutes les lignes qui ont une information manquante
NAdansarr_delay(variable qui enregistre le retard de chaque vol lorsqu’il est arrivé à destination - les vols avec unarr_delaynégatif sont arrivés plus tôt que prévu). - Regroupez les données par
carrier(code transporteur) - Calculer
avg_delay: le retard moyen par groupecarrier - Organisez les groupes
carrierpar ordre décroissant en fonction de la valeur deavg_delay. Les compagnies aériennes avec les retards moyens les plus importants apparaîtront en haut de la liste.
Utilisez les fonctions de {dplyr} dans le bloc de code ci-dessous pour répondre à la question : Quelles compagnies aériennes ont les retards moyens les plus importants ?
flights |>
drop_na(arr_delay) |>
group_by(carrier) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay))airlines
Nos résultats montrent que la compagnie aérienne dont le code
transporteur est F9 a enregistré le pire record de retards
dans la région de New York en 2013. Mais à moins d’être contrôleur de la
circulation aérienne, vous ne savez probablement pas quelle compagnie
aérienne a le code transporteur F9.
Heureusement, le package {nycflights13} est livré
avec un autre jeu de données, airlines, qui fait
correspondre le nom de chaque compagnie aérienne à son code
transporteur.
Jointure
Une première stratégie consisterait à rechercher manuellement
F9 dans airlines, puis répéter ce processus
pour tous les autres codes. Mais cette tâche serait fastidieuse et ne
serait pas agréable.
Une meilleure solution consisterait à utiliser un programme pour
joindre le jeu de données airlines à vos résultats
précédents. En d’autres termes, il faudrait demander à R d’ajouter le
nom (name) associé à chaque code transporteur dans
airlines à la ligne associée au code transporteur
correspondant dans vos résultats.
C’est ici que les fonctions de jointure interviennent. Les quatre
fonctions de jointure du package {dplyr} sont :
left_join(), right_join(),
full_join() et inner_join(). Chacune effectue
une variation de la tâche de base décrite ci-dessus.
Jeu de données pédagogique
Le moyen le plus simple d’apprendre le fonctionnement des fonctions
de jointure est d’essayer de le comprendre visuellement. À cette fin,
nous avons créé quelques petits jeux de données pédagogiques que nous
pouvons visualiser dans leur intégralité : band et
instrument. Ils ressemblent à ceci :
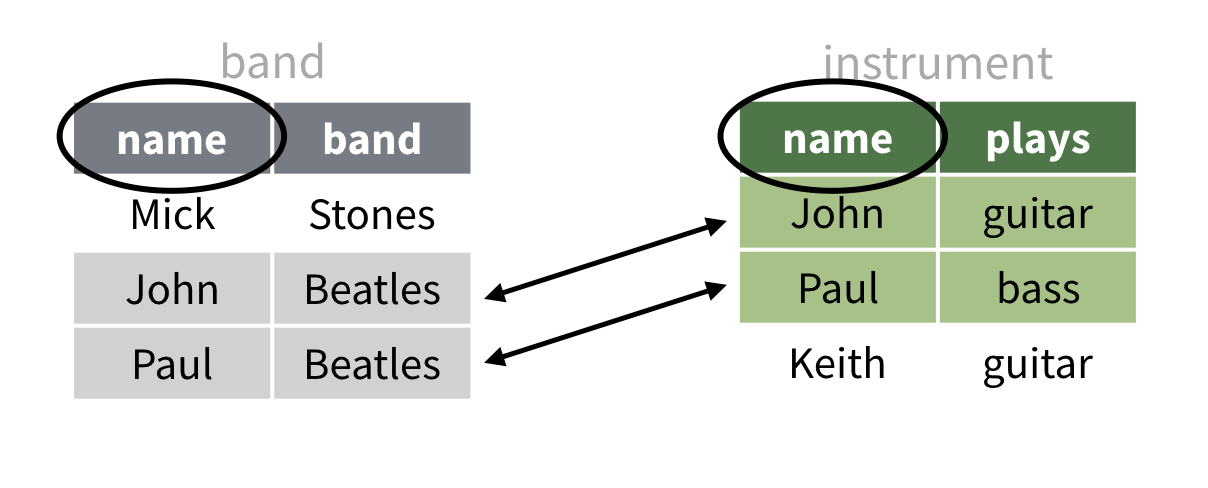
Notez que chaque jeu de données a une colonne nommée
name. Notez également que chaque jeu de données contient
une ligne sur John et une ligne sur Paul. Si vous en savez un peu sur
les Beatles, vous reconnaîtrez que ces lignes correspondent : elles
décrivent les mêmes personnes. D’un autre côté, les lignes nommées Mick
et Keith ne correspondent à aucune ligne de l’autre jeu de données.
Enfin, notez que les lignes correspondantes n’apparaissent pas au même
endroit dans chaque ensemble de données. Par exemple, John est dans la
deuxième ligne de band, mais la première ligne de
instrument.
Notre travail va consister à les réunir en un seul jeu de données qui fait correspondre correctement les lignes John et Paul.
Si vous souhaitez voir les données brutes disponibles dans
band et instrument, jetez un œil en exécutant
le code ci-dessous.
band
instrumentleft_join()
Examinons chaque fonction de jointure de {dplyr}, puis décomposons leur syntaxe.
La fonction left_join() renvoie une copie d’un jeu de
données qui est complétée par des informations provenant d’un deuxième
jeu de données. Elle conserve toutes les lignes du premier jeu de
données et n’ajoute que les lignes du deuxième jeu de données qui
correspondent aux lignes du premier.
Donc ici, Mick est conservé dans le résultat (avec un NA
à l’endroit approprié) car Mick apparaît dans le premier jeu de données.
En revanche, Kieth n’apparaît pas dans le résultat car Keith n’apparaît
pas dans le premier jeu de données.
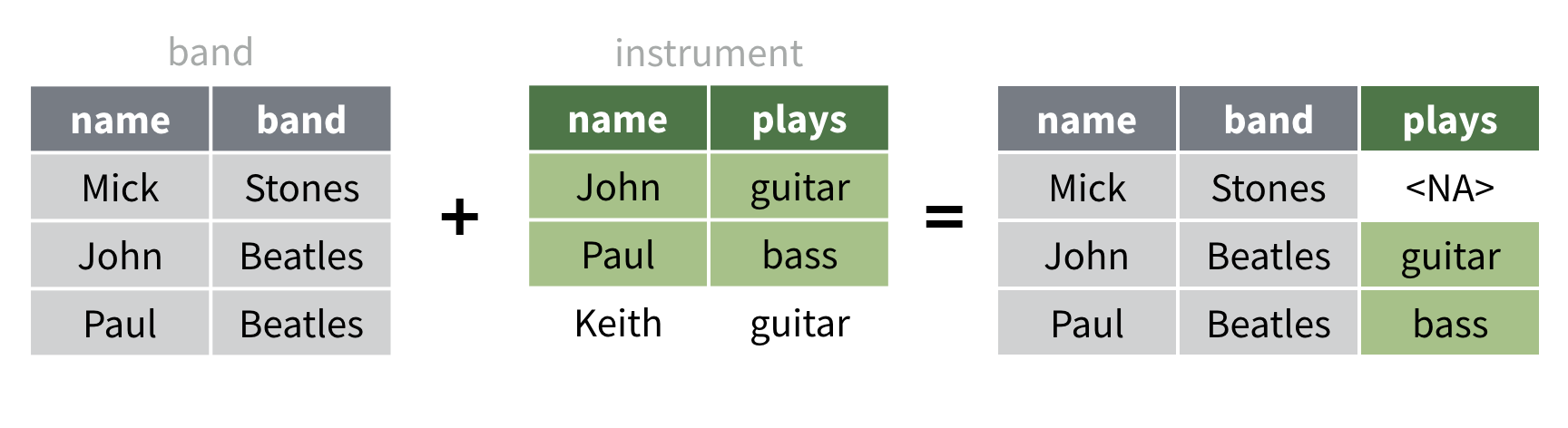
Pour voir à quoi ressemble ce résultat dans R, exécutez le code ci-dessous.
band |>
left_join(instrument, by = "name")right_join()
right_join() fait l’opposé de left_join() :
elle conserve chaque ligne du deuxième jeu de données et ajoute
uniquement les lignes du premier jeu de données qui ont une
correspondance dans le deuxième jeu de données. Maintenant, Keith
apparaît dans le résultat car Keith apparaît dans le deuxième jeu de
données. En revanche, Mick n’apparaît plus dans le résultat car il
n’apparaît pas dans le deuxième jeu de données.
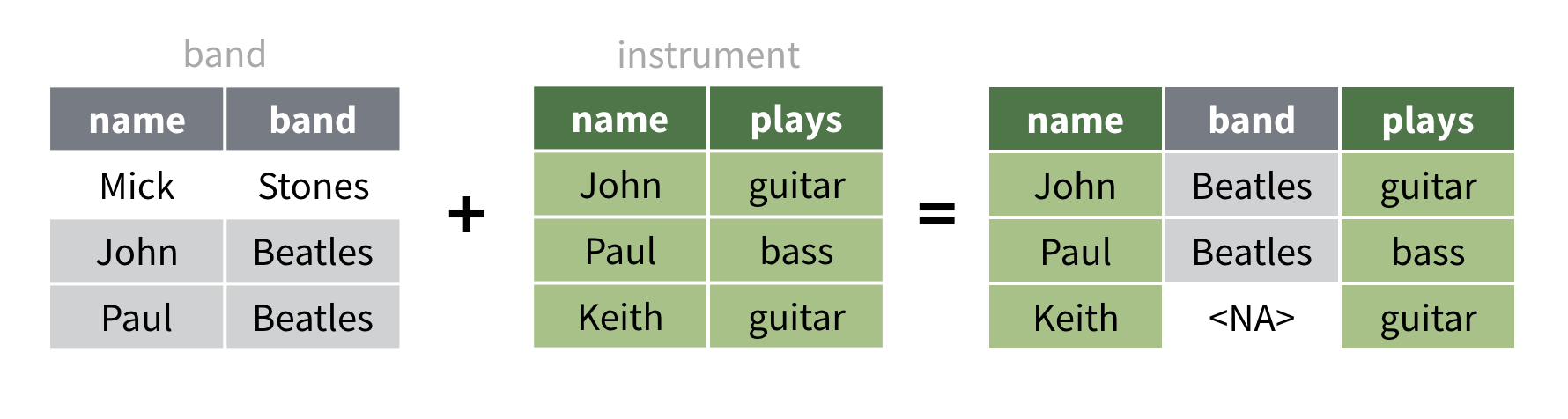
Vous pouvez penser à left_join() comme priorisant le
premier jeu de données, et à right_join() comme priorisant
le second. Pour voir les résultats dans R, exécutez le code
ci-dessous.
band |>
right_join(instrument, by = "name")Testez votre compréhension
Comment pouvez-vous échanger les noms dans le code ci-dessous pour obtenir les résultats illustrés dans le diagramme de jointure de droite ? (ne vous inquiétez pas de l’ordre des colonnes du résultat)
band |>
left_join(instrument, by = "name")instrument |>
left_join(band, by = "name")full_join()
Un full_join() est plus inclusif qu’un
right_join() ou un left_join(). Un
full_join() conserve toutes les ligne de chaque
jeu de données, en insérant des NA dans les résultats si nécessaire.
Il s’agit de la seule jointure qui ne perd aucune information des jeux de données d’origine. Mick et Kieth apparaissent dans les résultats.
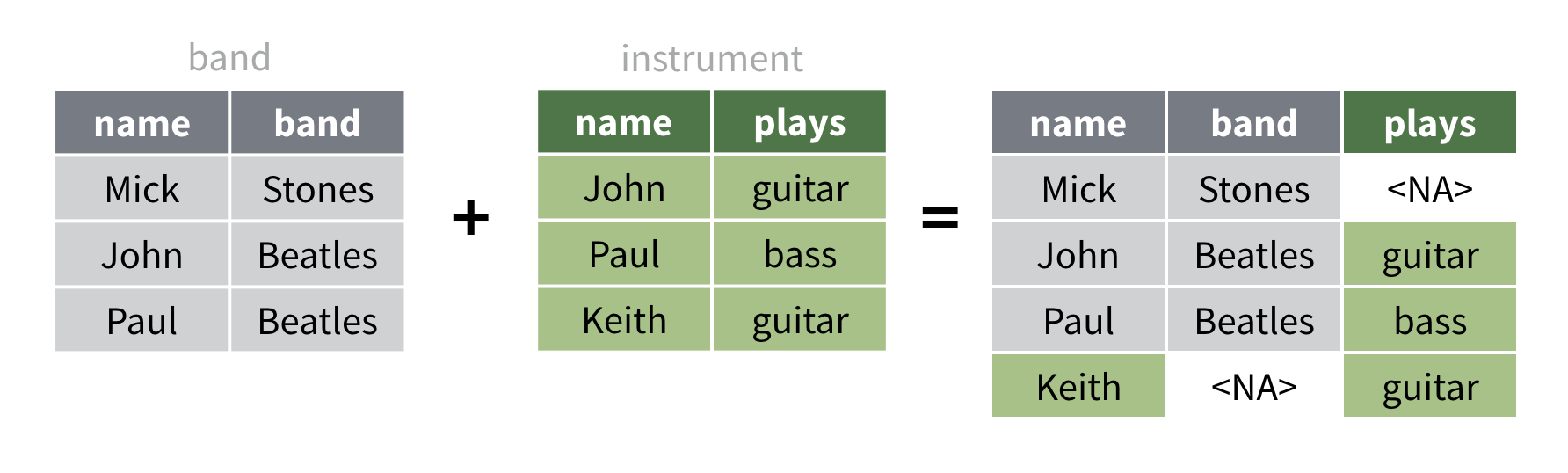
Pour voir à quoi ressemble ce résultat dans R, exécutez le code ci-dessous.
band |>
full_join(instrument, by = "name")inner_join()
En revanche, un inner_join() est la jointure la plus
exclusive. Elle ne conserve que les lignes qui apparaissent dans les
deux jeux de données. En conséquence, seuls John et Paul apparaissent
dans le résultat. Mick et Keith sont laissés de côté.
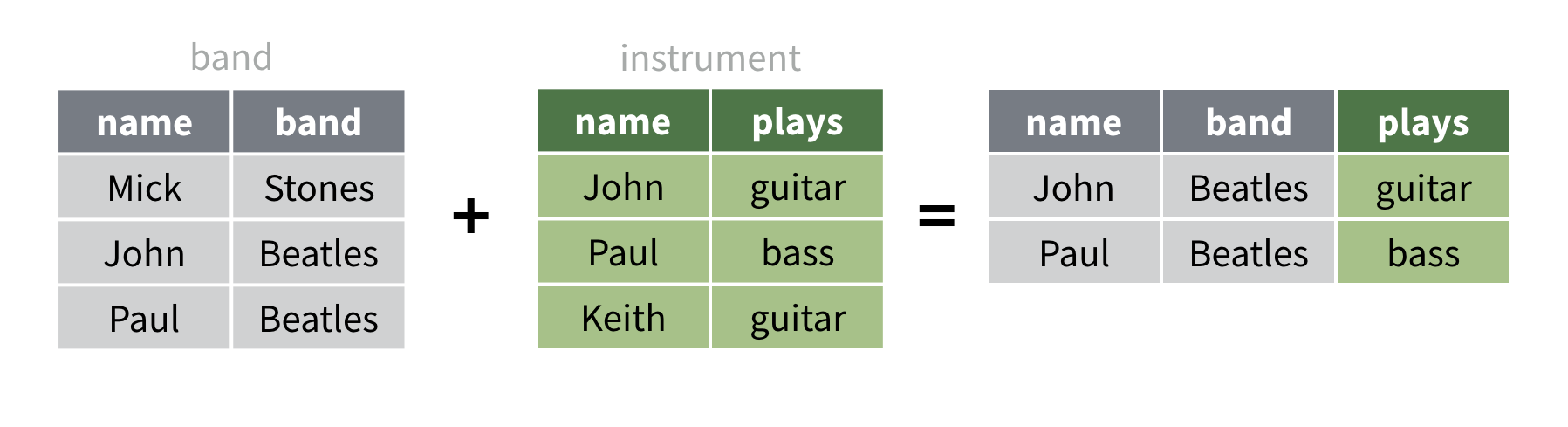
Pour voir à quoi ressemble ce résultat dans R, exécutez le code ci-dessous.
band |>
inner_join(instrument, by = "name")Syntaxe des jointures transformantes
Ces quatre jointures, left_join(),
right_join(), full_join() et
inner_join (), sont appelées jointures
transformantes (mutating joins en anglais). Pourquoi ? Car elles
renvoient chacune une copie d’un jeu de données qui a été augmentée de
nouvelles informations, tout comme mutate() renvoie une
copie d’un jeu de données qui a été enrichi de nouvelles
informations.
Chaque fonction utilise la même syntaxe :
left_join(band, instrument, by = "name")
right_join(band, instrument, by = "name")
full_join(band, instrument, by = "name")
inner_join(band, instrument, by = "name")Tout d’abord, transmettez à la fonction les noms de deux jeux de données à joindre.
Ensuite, définissez l’argument by : il correspond au(x)
nom(s) de la (ou des) colonne(s) à utiliser pour réaliser la jointure.
Ces noms doivent être transmis comme un vecteur de chaînes de
caractères, c’est-à-dire des caractères entourés de guillemets. Dans le
code ci-dessus, nous réalisons la jointure sur une seule colonne. C’est
pourquoi notre vecteur de chaînes de caractères n’est composé que d’une
seule chaîne. Mais vous pouvez imaginer faire quelque chose comme
left_join(band, instrument, by = c("first", "last")).
Pour que la jointure soit possible, chaque nom de colonne dans
by doit apparaître dans les deux jeux de données. La
fonction de jointure fera correspondre les lignes qui ont des
combinaisons identiques de valeurs dans les colonnes répertoriées dans
by. Si vous ne spécifiez pas d’argument by,
{dplyr} utilisera pour la jointure tous les noms de colonnes qui
apparaissent dans les deux jeux de données.
Exercice - Revenons-en à nos compagnies aériennes
Maintenant que vous vous êtes familiarisé avec les fonctions de jointure transformantes, utilisons-en une pour terminer notre enquête sur les compagnies aériennes. Ajoutez deux lignes supplémentaires au code ci-dessous.
- Dans la première, joignez les résultats à
airlinesde manière à garder chaque ligne de vos résultats précédents, mais uniquement les lignes deairlinespour lesquelles une correspondance est trouvée. - Dans la seconde, sélectionnez uniquement les colonnes
nameetavg_delay, dans cet ordre.
flights |>
drop_na(arr_delay) |>
group_by(carrier) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay))flights |>
drop_na(arr_delay) |>
group_by(carrier) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay)) |>
left_join(airlines, by = "carrier") |>
select(name, avg_delay)Jeux de données du package {nycflights13}
airlines n’est pas le seul jeu de données dans
{nycflights13} qui concerne les vols aériens. {nycflights13} contient au
total cinq jeux de données qui se concentrent chacun sur un aspect
connexe du transport aérien.
flights- décrit chaque vol au départ d’un aéroport de New York (c.-à-d. Newark, La Guardia ou JFK)airports- décrit les principaux aéroports des États-Unis, y compris leurs codes FAA (Federal Aviation Administration) et nomsplanes- décrit les différents avions, identifiés par le numéro indiqué sur la queue de l’appareilweather- décrit les conditions météorologiques horaires pour chaque aéroport de New Yorkairlines- répertorie les codes transporteurs et les noms de chaque compagnie aérienne
Le diagramme ci-dessous répertorie les noms de colonne pour chaque
jeu de données. Vous pouvez voir que chaque jeu de données partage une
ou plusieurs de ses colonnes avec flights. Utilisons-en un
pour répondre à une nouvelle interrogation.
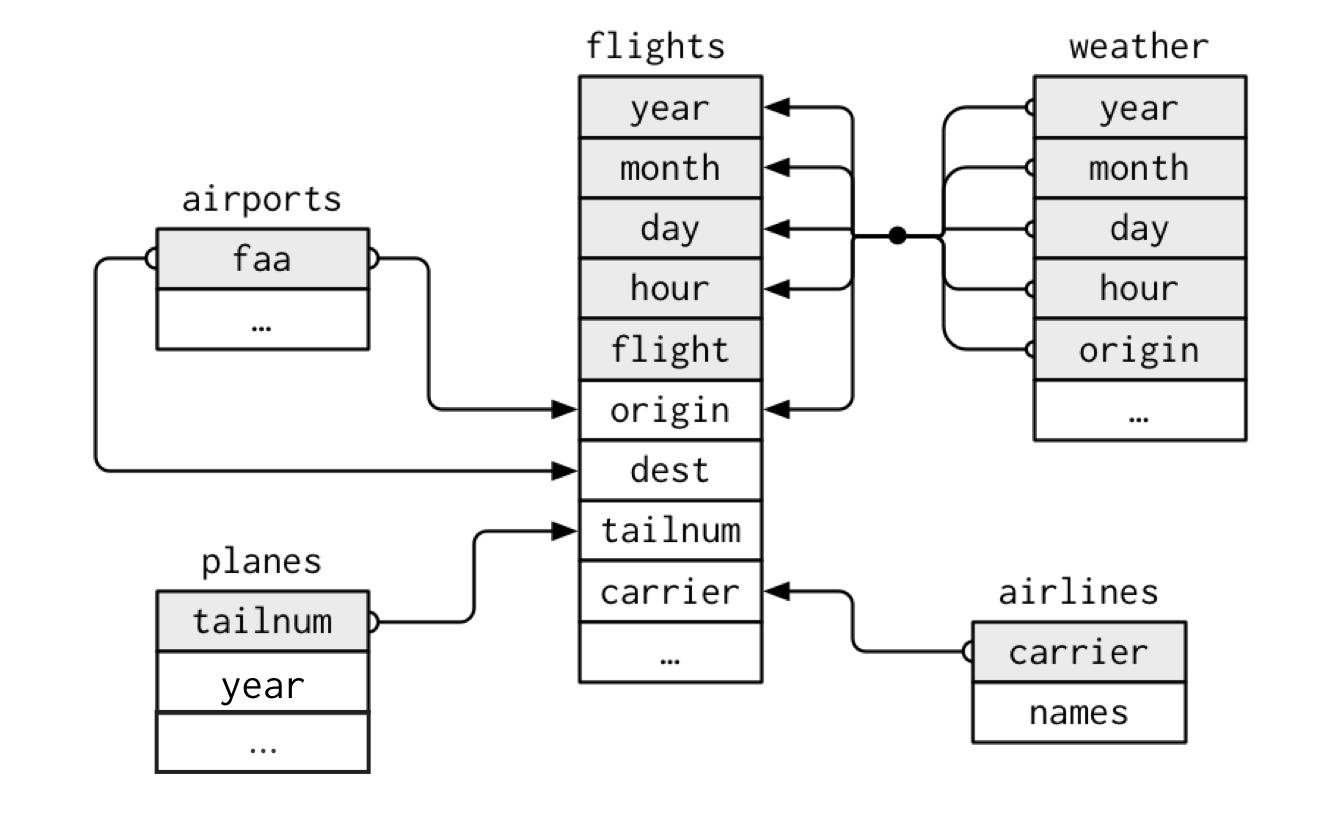
Quels aéroports ont les plus importants retards à l’arrivée ?
Répétons notre dernière investigation pour voir quelles destinations
ont les retards à l’arrivée moyens les plus importants. En échangeant
carrier avec dest, nous obtenons :
flights |>
drop_na(arr_delay) |>
group_by(dest) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay))Mais nous nous retrouvons confrontés à un problème similaire. Comment
remplacer les codes dest par des noms ?
airports
Heureusement, le jeu de données airports affiche les
noms associés à chaque code. Mais regardez attentivement
airports :
airportsNoms de colonnes différents
airports et flights partagent une variable
commune (les codes d’aéroport) mais enregistre la variable sous
différents noms de colonne : dest etfaa.
Il s’agit d’un phénomène courant avec les données. Nous pouvons
recréer ce phénomène avec les jeux de données instrument et
band. Pour cela, créons un jeu de données
instrument2 qui remplace le nom de colonne actuel
name de instrument par
artist.
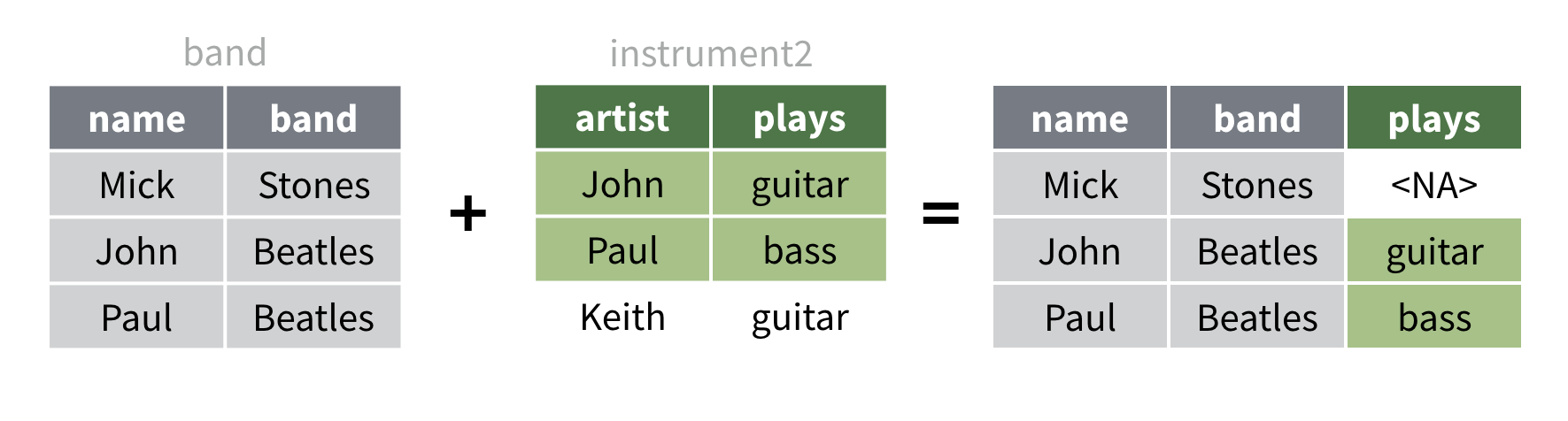
instrument2Nous pouvons toujours joindre band à
insturment2, mais nous devrons dire à R de faire
correspondre la colonne name à la
colonneartist. Pour ce faire, vous aurez besoin de savoir
les bases de comment nommer les éléments d’un vecteur.
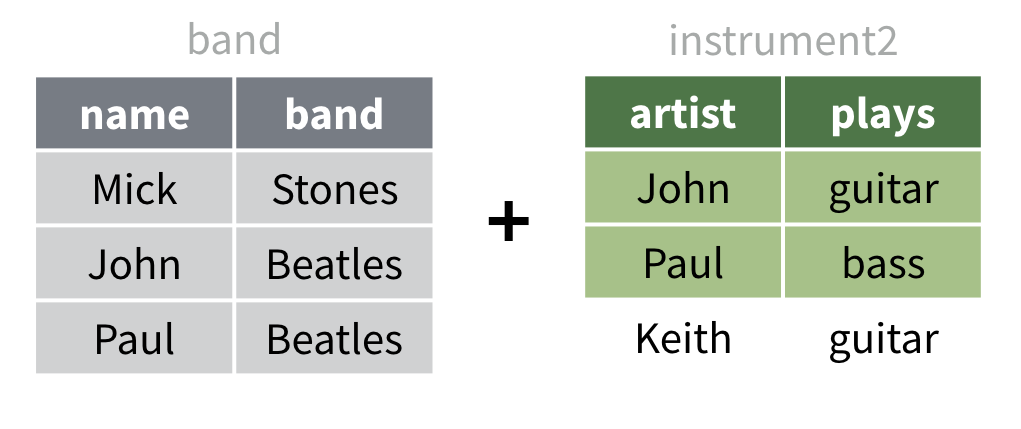
Vecteurs nommés
Un vecteur nommé est un vecteur dont les éléments ont reçu des noms.
Pour créer un vecteur nommé, attribuez des noms à chaque élément du
vecteur lorsque vous créez le vecteur avec c().
Par exemple, le code suivant crée un vecteur qui n’est pas nommé :
c(1, 2, 3)## [1] 1 2 3Alors que le code suivant crée un vecteur nommé. Ici, le premier élément est nommé “uno”, le second “dos”, et ainsi de suite.
c(uno = 1, dos = 2, tres = 3)## uno dos tres
## 1 2 3Si vous le souhaitez, vous pouvez placer des guillemets autour des
noms lorsque vous créez le vecteur, comme
c("uno" = 1, "dos" = 2, "tres" = 3). Nous ferrons cela dans
la section suivante pour rendre les choses symétriques.
Les vecteurs nommés sont une fonctionnalité de base de R. Voyons comment nous pouvons les utiliser pour résoudre notre problème de jointure.
Faire correspondre des noms de colonnes
Pour faire correspondre des colonnes avec des noms différents,
changez l’argument by de votre fonction de jointure pour
passer d’un vecteur de chaînes de caractères à un vecteur nommé
de chaînes de caractères.
band |>
left_join(instrument2, by = c("name" = "artist"))R fera correspondre la colonne name du premier jeu de
données à la colonne artist du deuxième jeu de données.
Pour voir à quoi ressemble le résultat dans R, exécutez le code ci-dessous.
band |>
left_join(instrument2, by = c("name" = "artist"))Deux détails
Vous pouvez utiliser cette syntaxe pour décrire plusieurs paires de colonnes. Par exemple :
foo |>
left_join(foo2, by = c("first" = "artist1", "last" = "artist2"))Techniquement, vous n’avez pas besoin d’entourer les noms du vecteur de guillemets. Cela fonctionnerait sans.
foo |>
left_join(foo2, by = c(first = "artist1", last = "artist2"))Mais vous devez obligatoirement utiliser des guillemets dans les
éléments du vecteur, qui sont des chaînes de caractères. Nous aimons
utiliser des guillemets des deux côtés du = pour la
parité.
Exercice - Quels aéroports ont les retards à l’arrivée les plus importants ?
Complétez le code ci-dessous pour afficher le nom de chaque destination jumelé à son retard à l’arrivée moyen.
flights |>
drop_na(arr_delay) |>
group_by(dest) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay))flights |>
drop_na(arr_delay) |>
group_by(dest) |>
summarise(avg_delay = mean(arr_delay)) |>
arrange(desc(avg_delay)) |>
left_join(airports, by = c("dest" = "faa")) |>
select(name, avg_delay)Récapitulatif sur les jointures transformantes
Les quatre fonctions de jointure couvrent toutes les façons dont vous pouvez combiner les informations d’un jeu de données avec un autre jeu de données.
left_join()- joint les données pertinentes du second à celles du premier (pertinentes dans le sens ‘données présentes également dans le premier jeu de données’)right_join()- joint les données pertinentes du premier à celles du second (pertinentes dans le sens ‘données présentes également dans le second jeu de données’)full_join()- conserve toutes les donnéesinner_join()- conserve uniquement les observations qui apparaissent dans les deux jeux de données
Si vous souhaitez combiner plus de deux jeux de données, vous pouvez
exécuter les jointures de manière séquentielle : joindre d’abord deux
jeux de données, puis joindre le résultat à un troisième, et ainsi de
suite. Ce processus est facile à automatiser avec la fonction
reduce() du package {purrr}.
Dans la section suivante, nous allons aborder un groupe de jointures qui font quelque chose d’étonnamment différent.
Jointures filtrantes
Destinations
Regardons de plus près les destinations des vols au départ de New York.
Pour ce faire, nous utiliserons un nouveau type de jointure : une jointure filtrante. Les jointures filtrantes sont différentes des jointures transformantes dans la mesure où elles n’ajoutent pas de nouvelles données à un jeu de données. Au lieu de cela, elles filtrent les lignes d’un jeu de données selon la correspondance ou non de ses lignes aux lignes d’un deuxième jeu de données.
{dplyr} est livré avec deux fonctions de jointures filtrantes :
semi_join()anti_join()
Les deux suivent la même syntaxe que les jointures transformantes.
semi_join()
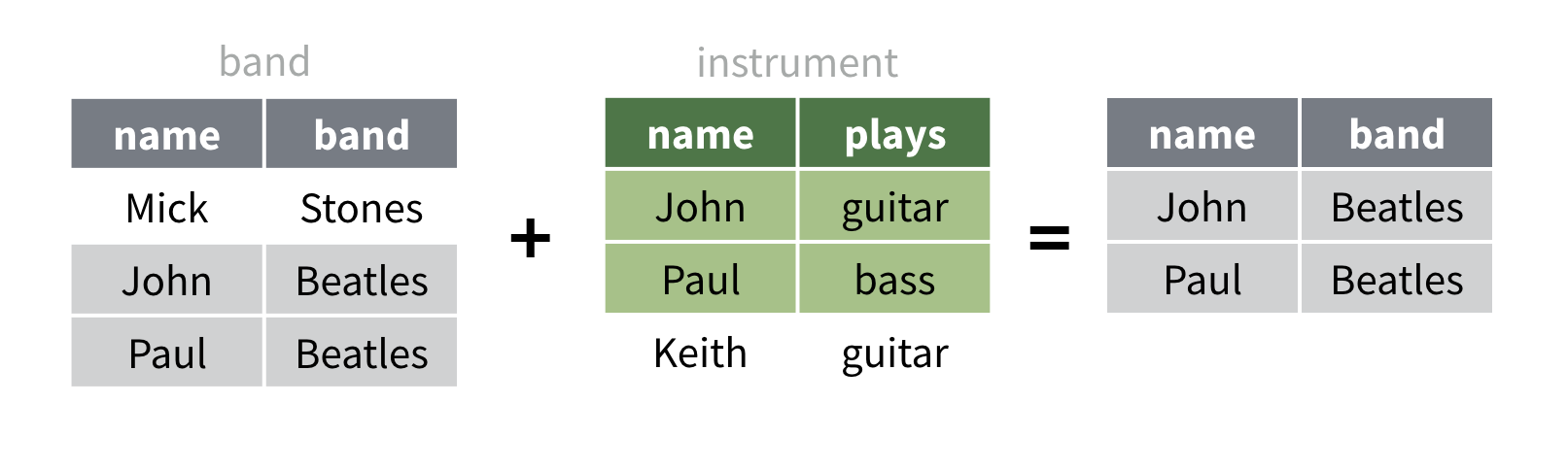
semi_join() renvoie chaque ligne du premier jeu de
données qui a une correspondance dans le deuxième jeu de
données. Ainsi, par exemple, semi_join() retourne les
lignes John et Paul de band. Notez que
semi_join() n’a rien ajouté à ces lignes.
Pour voir à quoi ressemblent les résultats dans R, exécutez le code ci-dessous.
band |>
semi_join(instrument, by = "name")anti_join()
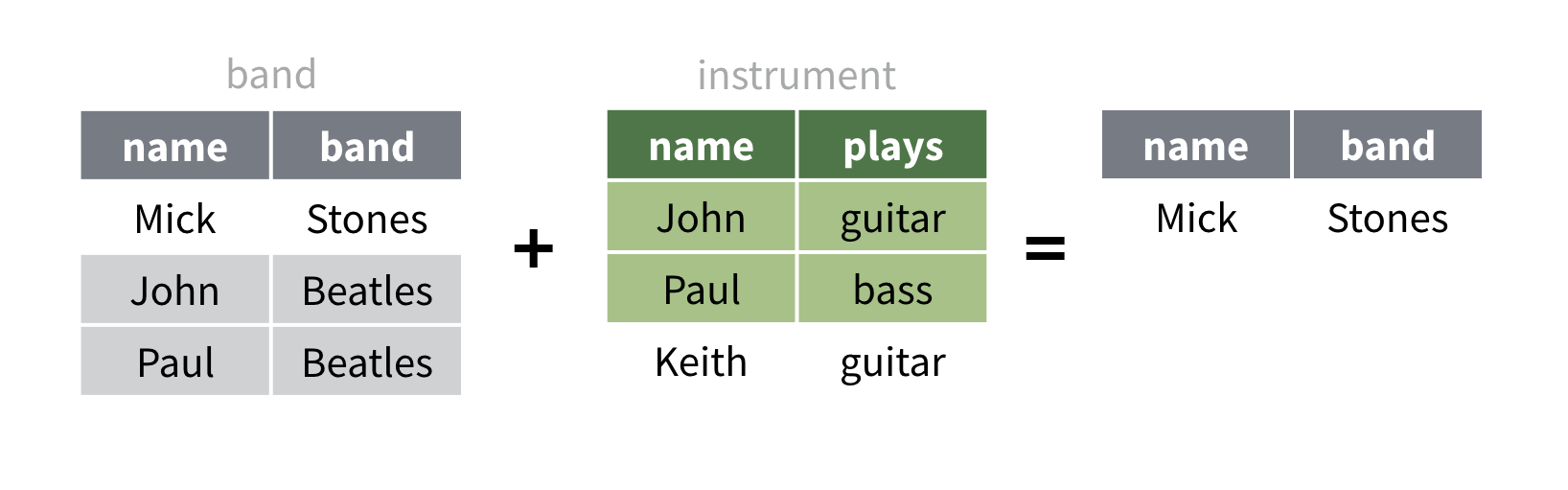
anti_join() fait exactement le contraire de
semi_join() : il renvoie toutes les lignes du premier jeu
de données qui n’ont pas de correspondance dans le deuxième jeu
de données.
Pour voir à quoi ressemblent les résultats dans R, exécutez le code ci-dessous.
band |>
anti_join(instrument, by = "name")distinct()
Nous utiliserons également une nouvelle fonction de {dplyr} :
distinct(). distinct() n’est pas une fonction
de jointure, mais elle est incroyablement utile. distinct()
renvoie les valeurs distinctes d’une colonne.
instrument |>
distinct(plays)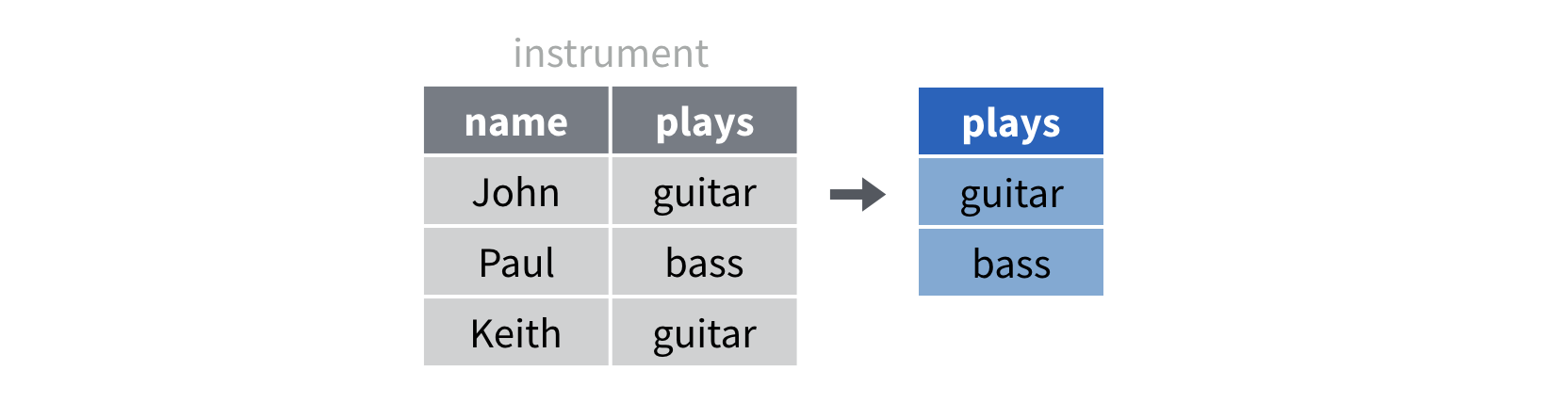
Si vous ne lui fournissez pas de colonne, distinct()
renvoie les lignes distinctes du jeu de données, en supprimant
les doublons. Elle dédoublonne les données.
Maintenant, mettons ces trois fonctions au travail.
À combien d’aéroports est connecté New York ?
Utilisez distinct() ci-dessous pour déterminer le nombre
d’aéroports auxquels New York est connecté. Ce sera le nombre de
destinations distinctes dans l’ensemble de données flights.
Créez d’abord un jeu de données avec ces destinations, puis recherchez
le nombre de lignes dans les données (il apparaît sous le tableau dans
les résultats).
flights |>
distinct(dest)Exercice - Remplacer les codes avec des noms
Remplaçons maintenant ces codes par des noms interprétables.
Complétez le code ci-dessous pour joindre à gauche nos résultats aux
aéroports (jeu de données airports). N’oubliez pas que les
deux jeux de données utilisent des noms de colonne différents.
Sélectionnez ensuite uniquement la colonne name.
flights |>
distinct(dest)flights |>
distinct(dest) |>
left_join(airports, by = c("dest" = "faa")) |>
select(name)Les NA
Si nous revenons un peu en arrière sur nos résultats, nous pouvons
voir que certains codes ne correspondaient pas au jeu de données
airports.
flights |>
distinct(dest) |>
left_join(airports, by = c("dest" = "faa")) |>
select(dest, name)Quels codes ne correspondaient pas ?
C’est inattendu. Il serait utile de voir quels codes ne correspondent
pas. Complétez le code ci-dessous avec une jointure filtrante pour
renvoyer uniquement les lignes qui n’ont pas de correspondance dans
airports.
flights |>
distinct(dest)flights |>
distinct(dest) |>
anti_join(airports, by = c("dest" = "faa"))Double vérification avec anti_join()
anti_join() permet de vérifier facilement une jointure.
Elle indique si toutes les lignes qui, selon vous, auront une
correspondance auront réellement une correspondance.
Il n’est pas rare que anti_join() renvoie des valeurs
qui ont une faute d’orthographe ou une faute de frappe qui empêche la
jointure. N’oubliez pas que la faute de frappe peut se trouver dans l’un
ou l’autre des jeux de données.
Ici, ceux-ci semblent être de vrais codes d’aéroports qui ont été mis
de côté dans airports. Nous ne pouvons pas vérifier les
noms de ces quatre aéroports parce que, par définition, ils ne figurent
pas dans notre jeu de données de noms d’aéroports.
Exercice - Combien de vols sont associés à un nom d’aéroport connu ?
Voyons comment cela affecte nos données. Utilisez le bloc de code
ci-dessous pour renvoyer tous les vols qui correspondent à un aéroport
dans airports. Veillez à utiliser une jointure filtrante,
et non une jointure transformante.
flights |>
semi_join(airports, by = c("dest" = "faa")) semi_join() pour filtrer des données
Comment écririez-vous une instruction filter() qui ne
trouve que les vols qui :
- Sont partis en janvier avec la compagnie JetBlue, ou
- Sont partis en février avec la compagnie Southwest ?
Cela peut être fait —tout comme de nombreux autres filtres complexes.
Mais vous pouvez trouver un moyen plus facile de le faire avec
semi_join() au lieu de filter().
Filtre semi_join() 1
Par exemple, vous pouvez créer un jeu de données contenant les combinaisons souhaitées :
criteria <- tribble(
~month, ~carrier,
1, "B6", # B6 = JetBlue
2, "WN" # WN = Southwest
)
criteriaEnsuite, vous pouvez exécuter un semi_join() sur le jeu
de données. Utilisez criteria et semi_join()
ci-dessous pour ne renvoyer que les vols partis en janvier sur JetBlue
ou en février sur Southwest.
flights |>
semi_join(criteria, by = c("month", "carrier"))Récapitulatif sur les jointures filtrantes
Les jointures filtrantes filtrent un jeu de données en fonction des observations d’un deuxième jeu de données. Elles sont appelées jointures car elles utilisent les informations des deux jeux de données. Cependant, elles utilisent ces informations pour filtrer —pas pour augmenter— les données d’origine.
semi_join()renvoie les lignes qui ont une correspondance dans le deuxième jeu de données. Elle fournit un raccourci utile pour un filtrage compliqué.anti_join()renvoie les lignes qui n’ont pas de correspondance dans le deuxième jeu de données. Il fournit un moyen utile de rechercher d’éventuelles erreurs dans une jointure.
distinct() n’est pas du tout une jointure, mais elle
filtre les jeux de données de manière utile.
Le dernier sujet de ce module couvrira des façons simples de combiner des jeux de données. Ces méthodes nécessitent que vos jeux de données soient pré-formatés pour s’emboîter.
Operations bind et set
Non-jointures
Les fonctions de jointure sont spécialisées dans les jeux de données qui sont liés les uns aux autres, mais qui ne sont pas préformatés pour s’emboîter.
Parfois, cependant, vous souhaiterez peut-être coller des ensembles de données qui “s’emboîtent” déjà, comme s’ils étaient divisés tels quels à partir d’un jeu de données maître. Les fonctions de cette rubrique vous montreront comment.
Comment combiner des colonnes qui s’alignent déjà ?
Considérez les deux jeux de données ci-dessous. Notez qu’ils
contiennent des variables différentes, mais des observations identiques.
Par exemple, la première ligne de beatles1 s’aligne avec la
première ligne debeatles2, la deuxième ligne s’aligne avec
la ligne rangée, et ainsi de suite.

Vous n’auriez pas besoin de faire une jointure pour combiner ces jeux de données, il vous suffirait de les coller ensemble. Comment peut-on faire cela ?
bind_cols()
Si vos jeux de données contiennent les mêmes observations, dans le
même ordre, vous pouvez les combiner avec bind_cols()

Exécutez le code ci-dessous pour voir à quoi ressemblent les résultats dans R.
beatles1 |>
bind_cols(beatles2)Notez que cela peut être dangereux de stocker vos données de cette
manière. En effet, il est difficile de s’assurer que les lignes d’un jeu
de données n’ont pas été mélangées. bind_cols() ne peut pas
dire si les lignes sont dans le bon ordre ou non, vous devrez donc être
prudent dans ces situations. En pratique on s’arrangera pour garder une
clé de jointure dans les 2 tables et ainsi pouvoir faire une jointure
dans les règles.
Comment combiner des lignes qui s’alignent déjà ?
Ces jeux de données présentent le cas contraire, qui est le plus
courant. Ici, chaque jeu de données contient les mêmes variables, mais
des observations différentes. Vous pourriez penser à band2
comme une continuation de band.
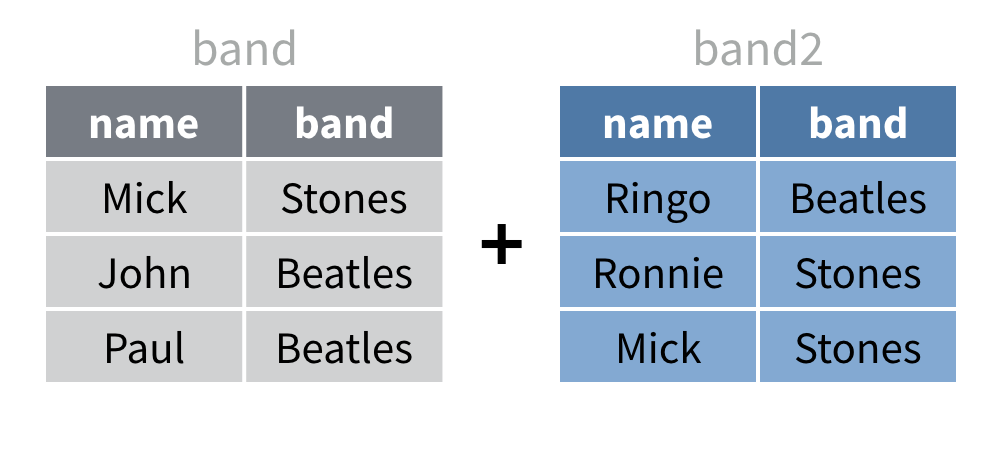
bind_rows()
Utilisez bind_rows() pour combiner des jeux de données
qui contiennent les mêmes variables, mais des observations
différentes.
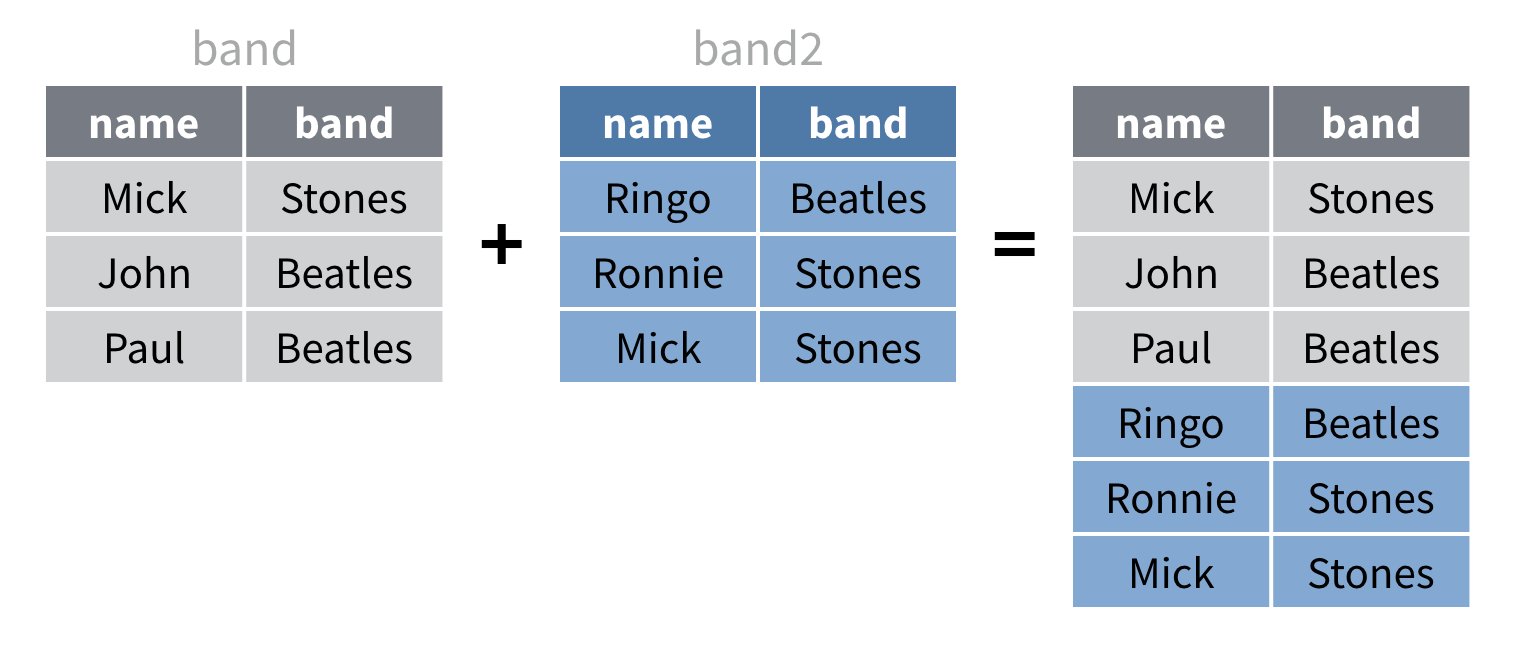
Exécutez le code ci-dessous pour voir à quoi ressemblent les résultats dans R.
band |>
bind_rows(band2).id
Lors de la combinaison de données avec bind_rows(), il
peut être utile d’ajouter une nouvelle colonne qui montre d’où vient
chaque ligne.
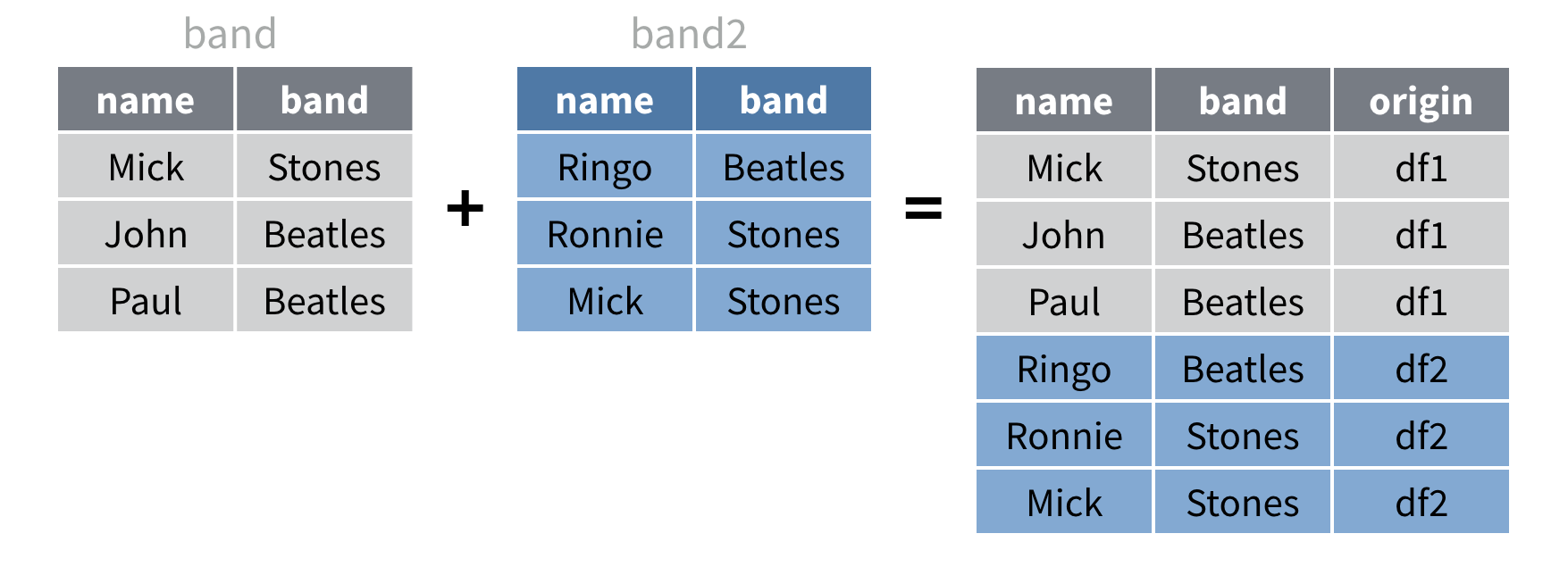
La façon la plus simple de procéder consiste à enregistrer les jeux
de données d’entrée sous forme de liste nommée et à appeler
bind_rows sur la liste. Ajoutez ensuite l’argument
.id à votre appel de bind_rows()et définissez
.id sur une chaîne de caractères. bind_rows()
utilisera la chaîne de caractères comme nom d’une nouvelle colonne qui
affiche le nom du jeu de données dont provient chaque ligne (tel que
déterminé par les noms dans la liste).
Si vous souhaitez rafraîchir votre compréhension des listes dans R, revoyez le module Bases de la programmation.
Ajoutez l’argument .id au code ci-dessous pour créer la
sortie affichée sur le graphique.
bands <- list(df1 = band,
df2 = band2)
bands |>
bind_rows()bands <- list(df1 = band,
df2 = band2)
bands |>
bind_rows(.id = "origin")Opérations set
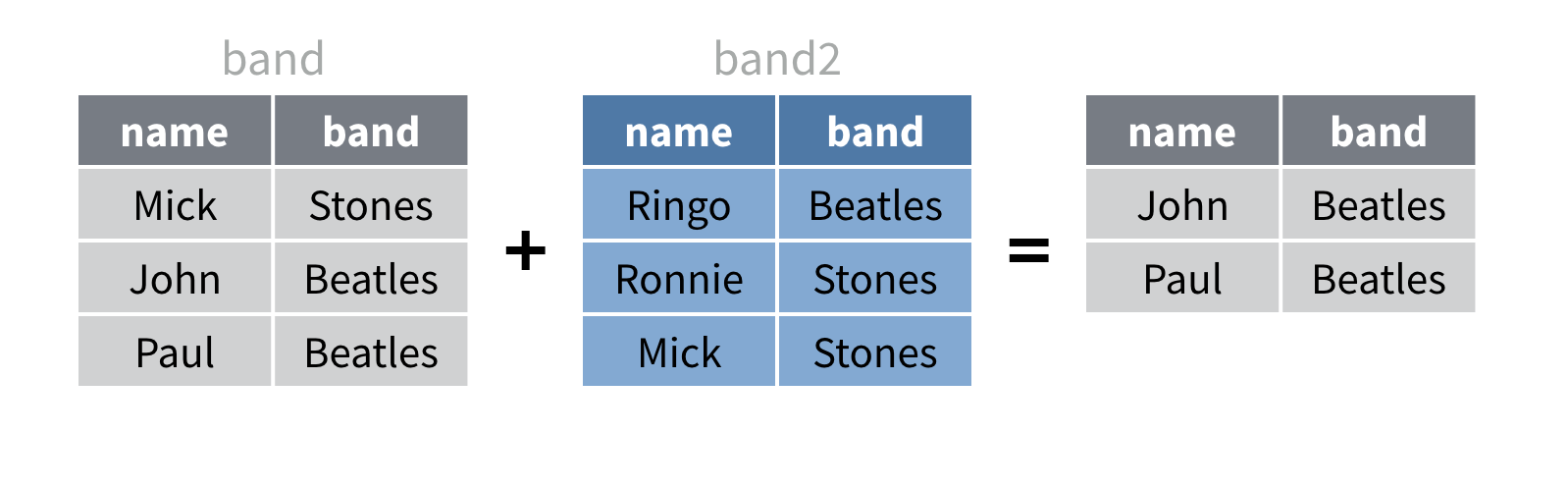
Avez-vous remarqué que band et band2
contiennent une ligne en double ? Chacun contient une ligne pour
Mick.
Lorsque vos jeux de données contiennent les mêmes variables et des ensembles d’observations qui se chevauchent, vous pouvez utiliser les opérations d’ensemble traditionnelles pour renvoyer un ensemble réduit de lignes tirées des jeux de données.
Imaginez ce que chacune des opérations d’ensemble ci-dessous renverra lorsqu’elle sera appliquée aux jeux de données ci-dessus. Exécutez ensuite le code pour vérifier si vous aviez raison.
band |>
union(band2)
band |>
intersect(band2)
band |>
setdiff(band2)
band2 |>
setdiff(band)union()
union() renvoie chaque ligne qui apparaît dans l’un ou
l’autre des jeux de données, mais elle supprime les copies en double des
lignes.
band |>
union(band2)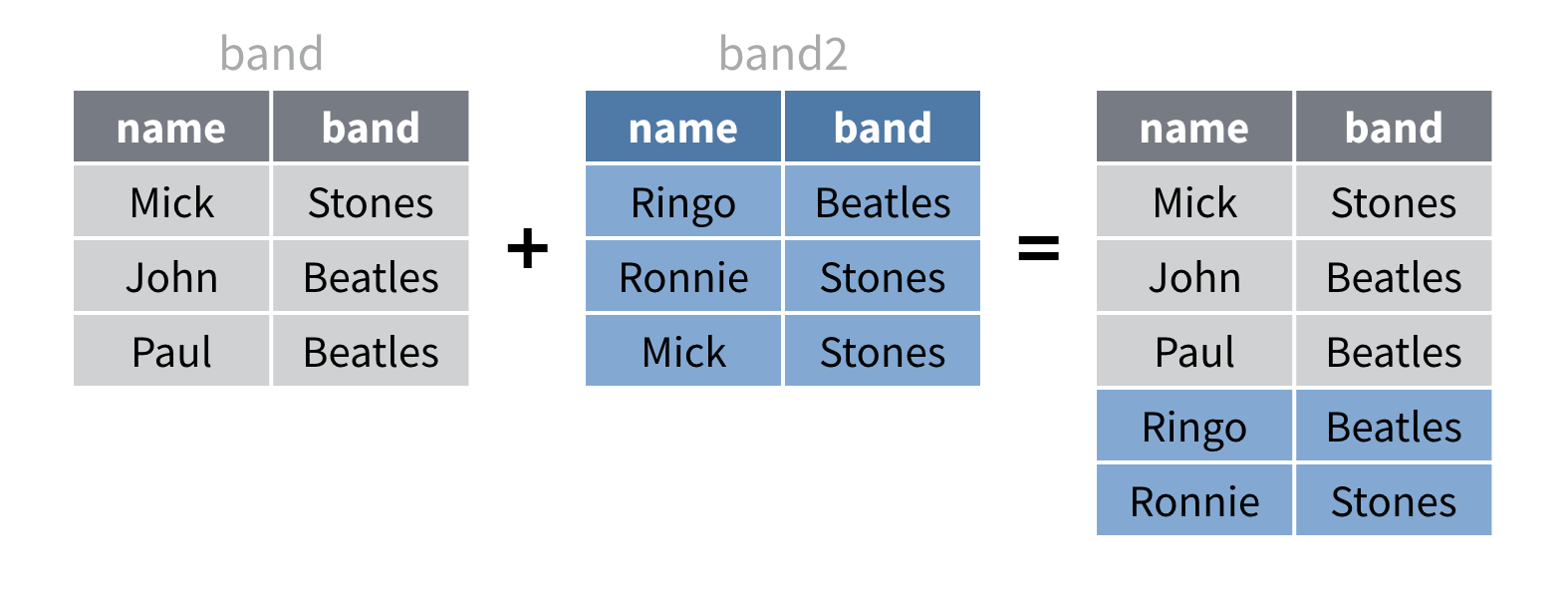
intersect()
intersect() renvoie uniquement les lignes qui
apparaissent dans les deux jeux de données. Elle supprime également les
copies en double de ces lignes.
band |>
intersect(band2)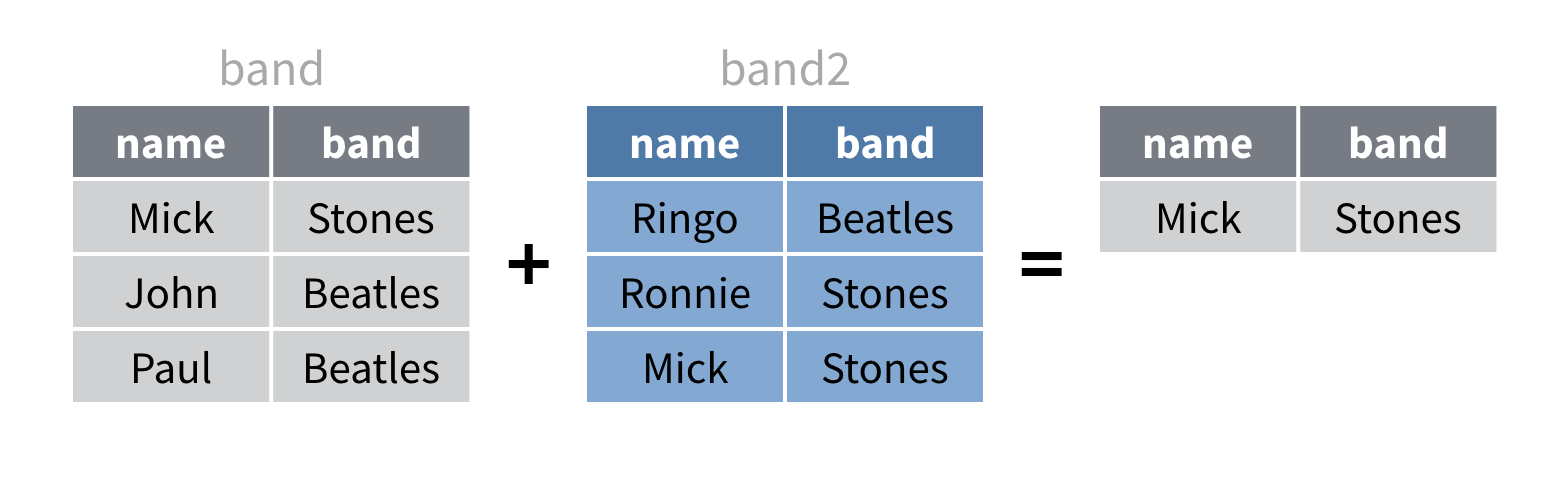
setdiff()
setdiff() retourne toutes les lignes qui apparaissent
dans le premier jeu de données mais pas dans le second.
band |>
setdiff(band2)